This paper investigates the problem of understanding dynamic 3D scenes from egocentric observations, a key challenge in robotics and embodied AI. Unlike prior studies that explored this as long-form video understanding and utilized egocentric video only, we instead propose an LLM-based agent, Embodied VideoAgent, which constructs scene memory from both egocentric video and embodied sensory inputs (e.g. depth and pose sensing). We further introduce a VLM-based approach to automatically update the memory when actions or activities over objects are perceived. Embodied VideoAgent attains significant advantages over counterparts in challenging reasoning and planning tasks in 3D scenes, achieving gains of 4.9% on Ego4D-VQ3D, 5.8% on OpenEQA, and 11.7% on EnvQA. We have also demonstrated its potential in various embodied AI tasks including generating embodied interactions and perception for robot manipulation. The code and demo will be made public.
TL;DR: We introduces Embodied VideoAgent, an LLM-based system that builds dynamic 3D scene memory from egocentric videos and embodied sensors, achieving state-of-the-art performance in reasoning and planning tasks.
Method
Embodied VideoAgent adopts the following memory and
tool design upon its predecessor VideoAgent: given an downsampled egocentric video,
with depth map and camera 6D pose of each frame, it constructs the original temporal memory of VideoAgent, the newly introduced Persistent Object Memory, and two simple history buffers.
Four tools (query_db, temporal_loc, spatial_loc, vqa) can be invoked to access the memory. Several embodied action primitives are available to be called to interact with the physical environment.
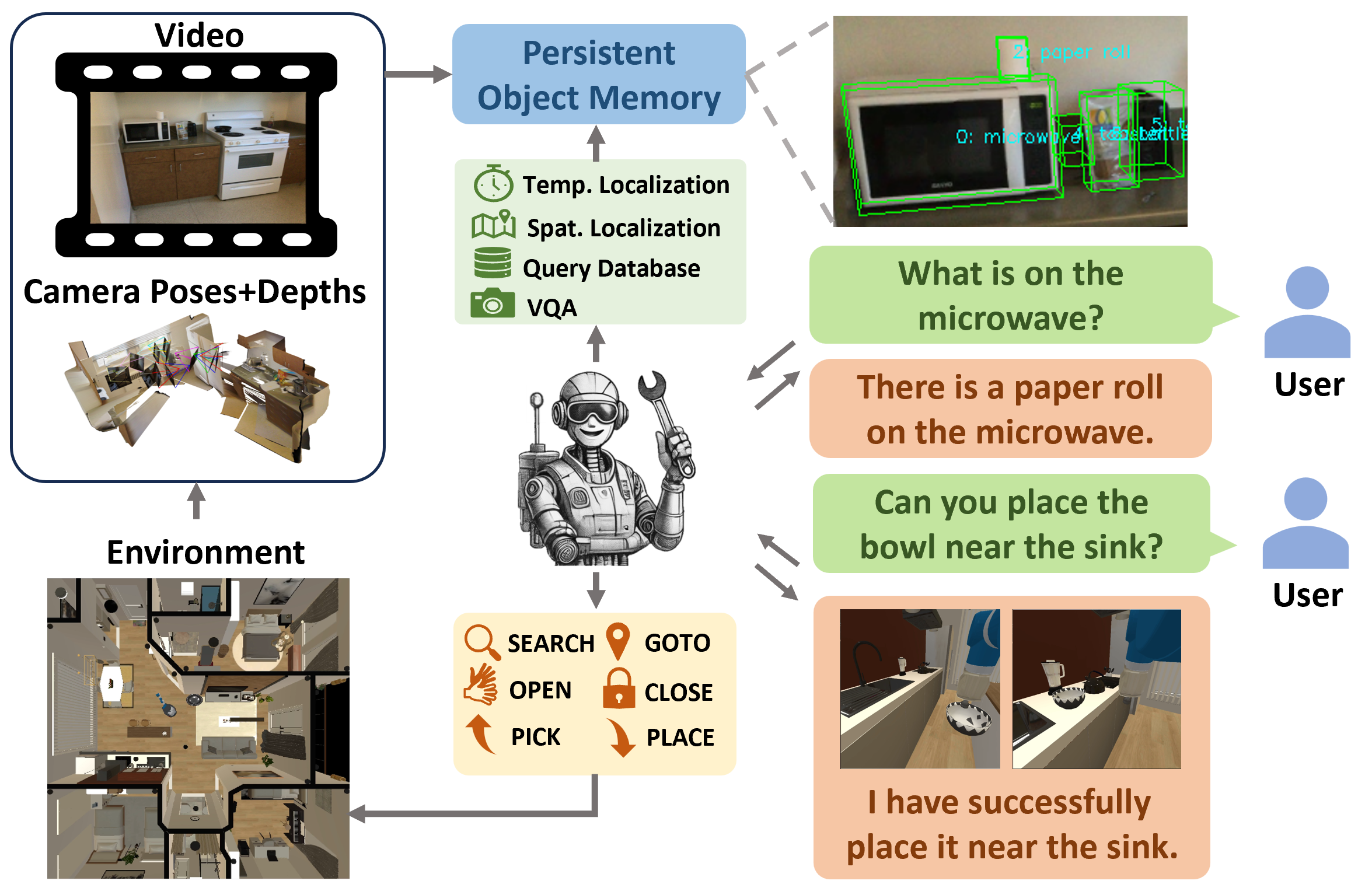
 Figure 2. An overview of Embodied VideoAgent. Left: We first translate the egocentric video and embodied sensory input (depth maps and camera poses) into structured representations: persistent object memory and history buffer. While the memory can be updated using VLM to support dynamic scenes where actions are being performed constantly; Right: the LLM within Embodied VideoAgent is prompted to fulfill the user's request by interactively invoking tools to query the memory and calling embodied action primitives to complete the task.
Figure 2. An overview of Embodied VideoAgent. Left: We first translate the egocentric video and embodied sensory input (depth maps and camera poses) into structured representations: persistent object memory and history buffer. While the memory can be updated using VLM to support dynamic scenes where actions are being performed constantly; Right: the LLM within Embodied VideoAgent is prompted to fulfill the user's request by interactively invoking tools to query the memory and calling embodied action primitives to complete the task.
Persistent Object Memory
As shown in Figure 2, Persistent Object Memory maintains an entry for each perceived object in the 3D scene. Each object entry includes the following fields: a unique object identifier with object category (ID), a state description of the object(STATE), a list of related objects and their relations (RO), 3D bounding box of the object(3D Bbox), visual feature of the object (OBJ Feat) and visual feature of the environment context where the object locates(CTX Feat). These fields provide comprehensive details of scene objects and their surroundings. The following figures are the visualization of Persistent Object Memory in both static and dynamic scenes.


Memory Update with VLM
A key challenge in Persistent
Object Memory lies in updating memory when actions are
performed on objects. We address this issue by leveraging action information and vision language models (VLMs). As shown in Figure 3, when an
action occurs (e.g., “C catches the can”), we first retrieve
relevant object entries associated with the “can” that
are visible in the current frame (in this example, two entries). For each entry, we render its 3D bounding box onto
the frame and prompt the VLM to determine if the object
within the box is the action's target. Such visual prompting associates the action with corresponding entries in the object memory. Finally, we programmatically update these entries, such as modifying the STATE field to “in-hand” since the action is “catches the can”.
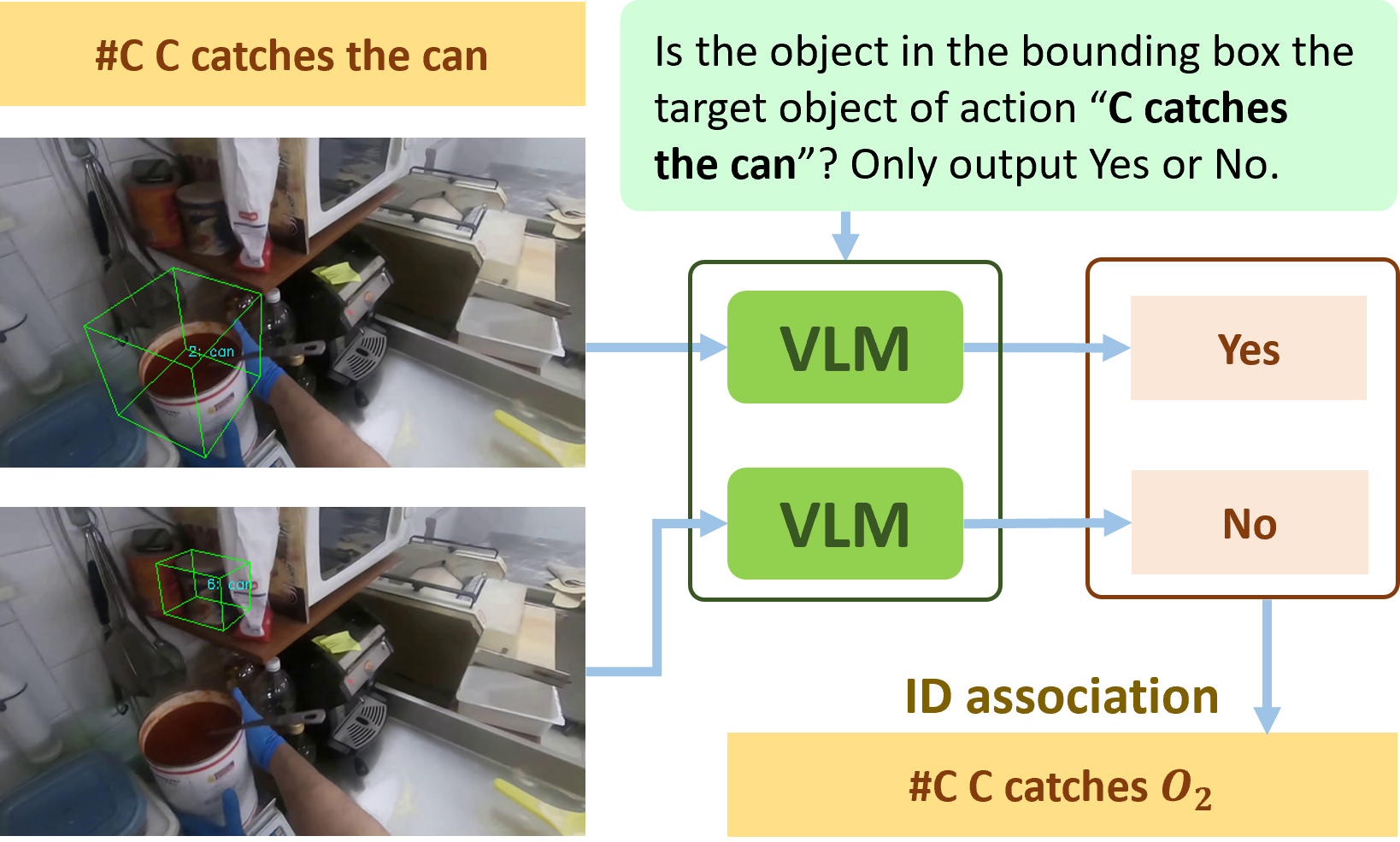 Figure 3. An illustration of our VLM-based memory update method.
This approach effectively prompts the VLM to associate an action
with relevant object entries in memory through visual prompting,
identifying the entries corresponding to the action's target objects.
Figure 3. An illustration of our VLM-based memory update method.
This approach effectively prompts the VLM to associate an action
with relevant object entries in memory through visual prompting,
identifying the entries corresponding to the action's target objects.
Tools and Action Primitives
We equip Embodied VideoAgent with four tools: query_db(·), which
processes natural language queries to retrieve the top-10
matching object entries by searching both the persistent
object memory and history buffers; temporal_loc(·),
inherited from VideoAgent, which maps natural language
queries to specific video timesteps; spatial_loc(·),
which provides a 3D scene location (aligned with the camera's coordinate system) based on object and room queries;
and vqa(·), which answers open-ended questions about
a given frame.
Additionally, the agent can perform seven
embodied action primitives: chat(·) for user interaction;
search(·) to conduct exhaustive scene searches for specified objects; goto(·) for location navigation; and open(·),
close(·), pick(·), and place(·) for object interactions.
A Two-Agent Framework for Generating Embodied Interactions
We explore a novel approach with
Embodied VideoAgent to gather synthetic embodied user-assistant interaction data. This dataset comprises episodes
where a user interacts with an assistant within embodied environments. We use one LLM to emulate the user's role, while Embodied VideoAgent assumes the assistant's role, exploring the environment and fulfilling the user's diverse
requests. An overview of this framework is shown in Figure 4. The user is prompted to propose varied and engaging tasks based on its limited scene graph knowledge achieved
by randomly trimming the full scene graph to stimulate curiosity and the assistant's feedback. Examples of the generated episodes can be found in Figure 5.
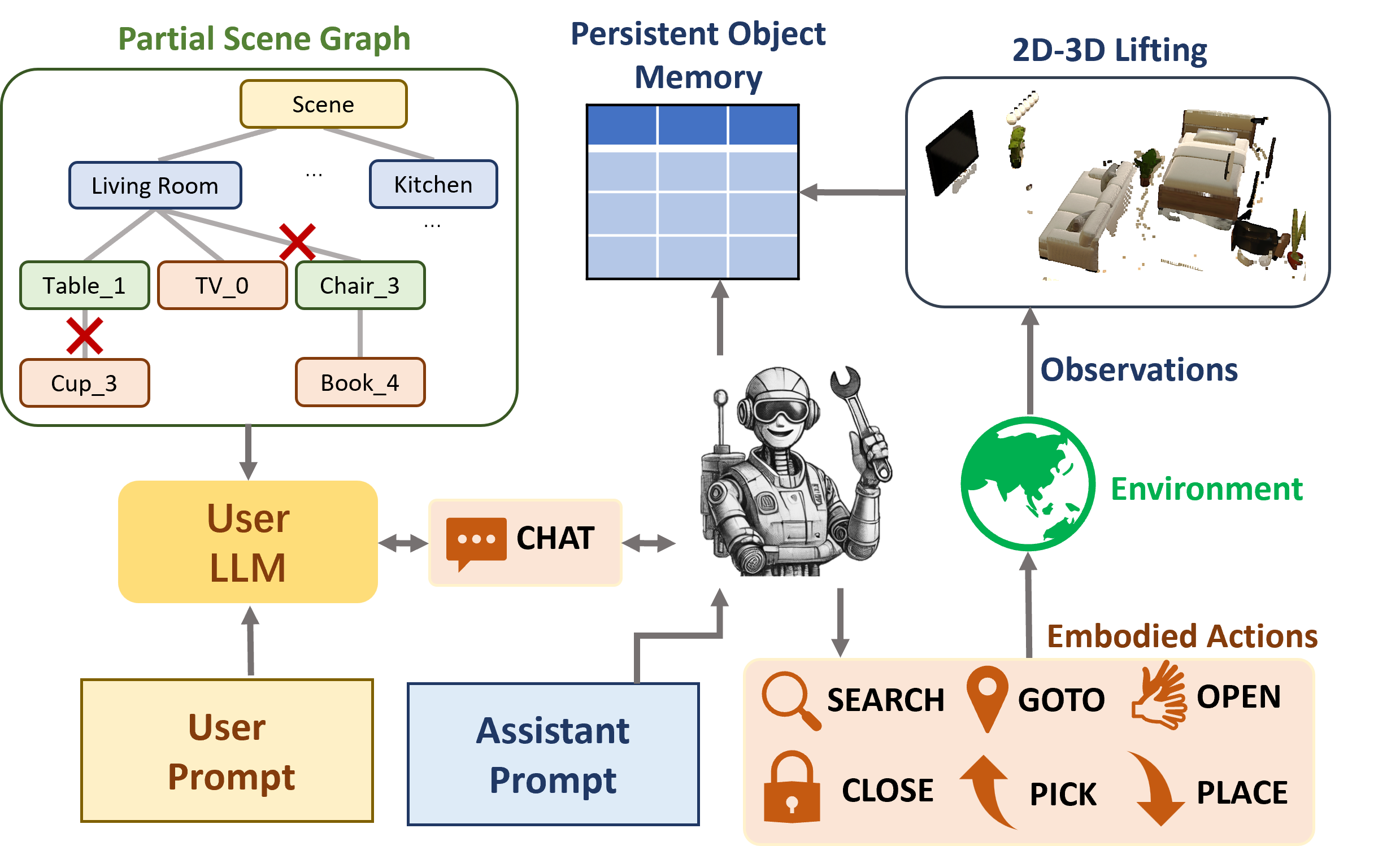 Figure 4. An overview of our synthetic embodied data collection
framework. An LLM plays the user role and is prompted to propose
engaging tasks based on a partial scene graph and the user's feedback, while the user, effectively a Embodied VideoAgent, explores
the scene and fulfills the user's requests.
Figure 4. An overview of our synthetic embodied data collection
framework. An LLM plays the user role and is prompted to propose
engaging tasks based on a partial scene graph and the user's feedback, while the user, effectively a Embodied VideoAgent, explores
the scene and fulfills the user's requests.
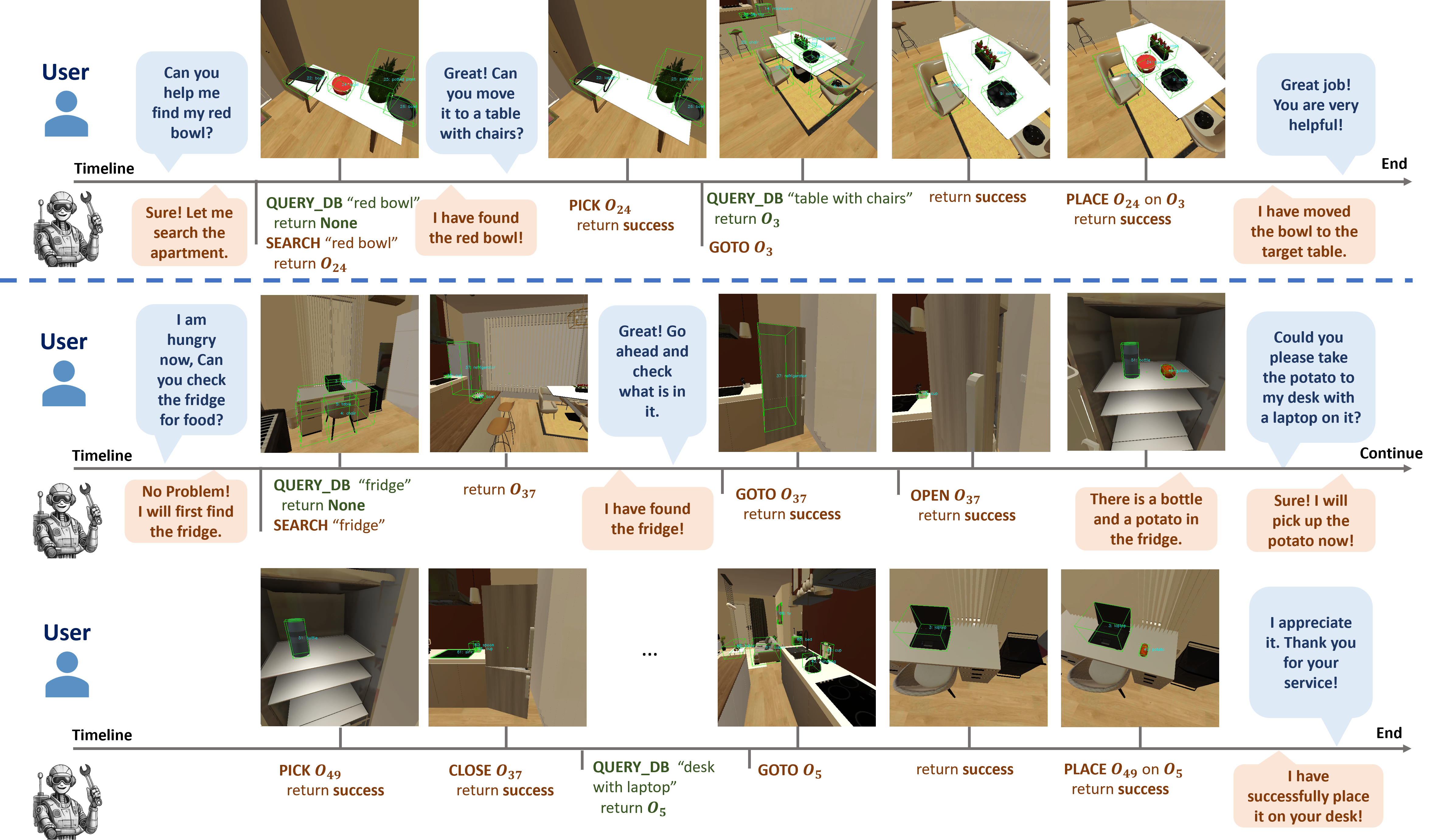 Figure 5. An episode of generated embodied user-assistant interaction. The episode is produced by the two-agent framework,
where an LLM plays the user and Embodied VideoAgent is the assistant. The episode comprises various embodied problem-solving that
requires precise memory of the scene objects and tool usage.
Figure 5. An episode of generated embodied user-assistant interaction. The episode is produced by the two-agent framework,
where an LLM plays the user and Embodied VideoAgent is the assistant. The episode comprises various embodied problem-solving that
requires precise memory of the scene objects and tool usage.
Applications
In Figure 6, we showcase Embodied VideoAgent's application in robotic perception, where a
Franka robot uses it to build persistent memory in a dynamic
manipulation scene. In this task, the robot is instructed to
pick up an apple. However, the apple later becomes hidden
behind a box, illustrating the dynamic nature of the scene.
Leveraging persistent object memory, the robot successfully
recalls the apple's location despite the obstruction and completes the task by first moving the box aside, demonstrating
the effectiveness of Persistent OBject Memory.
 Figure 6. Our persistent object memory enables effective real-world robotic manipulation.
Figure 6. Our persistent object memory enables effective real-world robotic manipulation.
BibTeX
@inproceedings{fan2025embodied,
title={Embodied videoagent: Persistent memory from egocentric videos and embodied sensors enables dynamic scene understanding},
author={Fan, Yue and Ma, Xiaojian and Su, Rongpeng and Guo, Jun and Wu, Rujie and Chen, Xi and Li, Qing},
booktitle={International Conference on Computer Vision},
year={2025},
}
 Embodied VideoAgent: Persistent Memory from Egocentric Videos and Embodied Sensors Enables Dynamic Scene Understanding
Embodied VideoAgent: Persistent Memory from Egocentric Videos and Embodied Sensors Enables Dynamic Scene Understanding